Robots.txt — файл в текстовом формате, в котором прописаны условия индексирования сайта поисковыми роботами. Правильный robots.txt укажет поисковой системе, что нужно индексировать в первую очередь, а от индексации чего следует воздержаться. Так же он подскажет адрес XML-карты сайта, определит основное зеркало, и многое другое. Во-первых, нужно отметить, что это не обязательный файл и можно обойтись без него, но в таком варианте поисковики будут индексировать все, что есть в наличии на вашем сайте. Согласитесь, есть много папок и файлов, которые нужно оградить от индексации по разным причинам, чтобы облегчить задачу поисковому боту, направив его в правильное русло для скорейшей индексации нужных файлов.

Файл robots.txt должен находиться в корневой директории сайта, он не генерируется при первичной установке WordPress, а создается и загружается самостоятельно или при помощи плагина All in One SEO Pack.

Если у вас установлен плагин Clearfy, в настройках этого замечательного и бесплатного модуля, на вкладке SEO Вы найдете уже готовый и предлагаемый именно для вашего сайта файл robots.txt.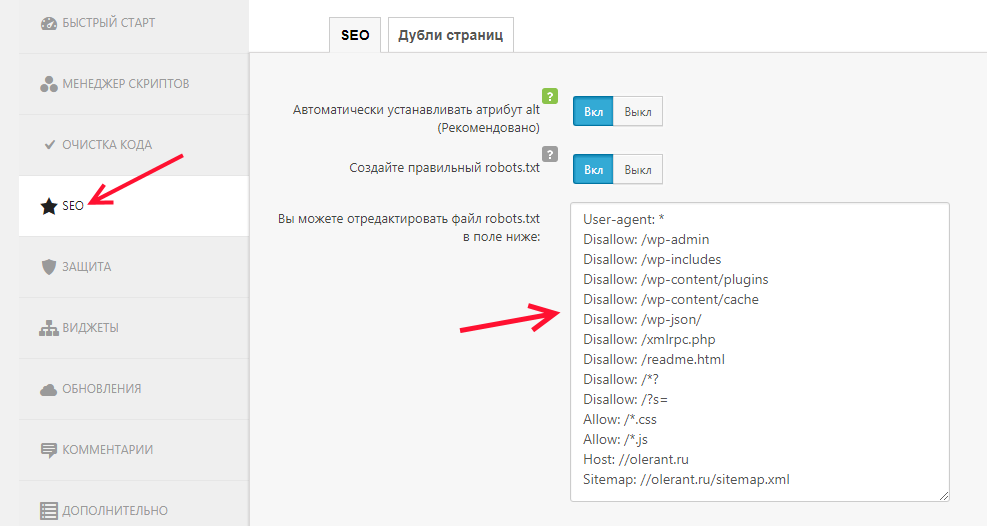
Для составления такого файла так же можно использовать онлайн-сервисы, например, «Создание Robots.txt»
//htmlweb.ru/analiz/robots.php
Несколько основных директив, которые нужно обязательно указывать в файле robots.txt:
- User-agent — начальная строка с указанием клиентского приложения или, проще говоря, поискового бота. Например,
User-agent: * — для всех поисковиков,
User-agent: Yandex — для Яндекса,
User-agent: Googlebot — для Гугла,
User-agent: StackRambler — для Рамблера,
User-agent: Slurp — для Yahoo и т.д. - Disallow — запрет индексации каталога или всех страниц, полное имя которых начинается с названия такого каталога. Например,
Disallow: /wp-admin/ запрещает посещение именно каталога wp-admin, а
Disallow: /wp-admin всего содержимого в каталоге.
Чтобы robots.txt считался корректным, должна присутствовать как минимум одна директива Disallow для каждого поля User-agent ; - Allow — разрешение доступа к сайту или определенным разделам. Например, при Disallow: /wp-admin/ Вы можете разрешить индексацию какого-нибудь отдельного вложенного каталога или файла: Allow: /catalog/file.php или Allow: /file.php;
- Crawl-delay — задание времени в секундах между окончанием загрузки одной страницы и началом загрузки следующей. При большой нагрузке на сервер это значение можно увеличить, чтобы «умерить пыл» индексирующего робота. Поддерживаются дробные значения, например, 4.5;
- Sitemap — указание пути к карте сайта в формате xml — файлу (файлам) sitemap.xml. Для создания файла sitemap можно использовать плагины All in One SEO или Google XML Sitemaps;
- Host — указание имени главного зеркала сайта (с www или без www).
Но! Не все эти директивы принимаются во внимание разными ботами, например, роботы Google, Rambler и Yahoo не могут распознать директиву Crawl-delay. Смотрите пример проверки файла robots.txt в Google webmaster:

Как же быть в таком случае? На многих сайтах обучающей тематики можно найти рекомендации создавать для каждого поисковика свой robots.txt. Несколько файлов с одним и тем же названием создать никак не получится, поэтому можно в одном файле разместить директивы конкретно для Яндекса и отдельно для других роботов. Избранные поисковые системы позиционируют себя этакими файлово-цифровыми гурманами и не собираются кушать все, что им предлагают. Вот, например, ситуация с User-agent: если Яндекс обнаруживает строку User-agent: Yandex, то директивы для User-agent: * в этом случае не учитываются. Исходя из такого правила, получается, что одна часть совмещенного файла robots.txt (с User-agent: *) будет предназначена для сторонних (произвольных) роботов, а другая (с User-agent: Yandex), соответственно, только для робота Яндекса. Например:
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Sitemap: https://www.site.ru/sitemap.xml Host: www.site.ru
User-Agent: Yandex Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Crawl-delay: 2 Sitemap: https://www.site.ru/sitemap.xml Host: www.site.ru
Из первой части (User-Agent: *) пришлось убрать директиву Crawl-delay, которая не учитывается роботами, отличными от Яндекса.

Приведу пример базового (начального) варианта файла robots.txt для WordPress, предназначенного для всех без исключения роботов:
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Crawl-delay: 2 Sitemap: https://www.site.ru/sitemap.xml Host: www.site.ru
Такой файл я взял за основу и использую на своем сайте. Вы можете заметить, что в предлагаемом robots.txt отсутствует запрет индексации страницы входа в админ-панель WordPress, каталог администратора и страницу регистрации нового пользователя. В этом нет необходимости, потому, что в свежих версиях CMS во все вышеупомянутые страницы сам WordPress по умолчанию добавляет тег «noindex», запрещающий их индексацию.
Можно скопировать этот код и вставить в заранее подготовленный текстовой документ в любом текстовом редакторе, присвоив ему имя robots и у Вас будет свой корректный файл robots.txt. Но, разумеется, его нужно дополнить под свой проект. Вы вправе внести коррективы в данный файл, например запретить индексирование любой папки или файла сайта, используя директиву Disallow. Не забудьте поменять домен сайта с site.ru на свой в директивах Host и Sitemap, определившись с главным зеркалом (с www или без www).

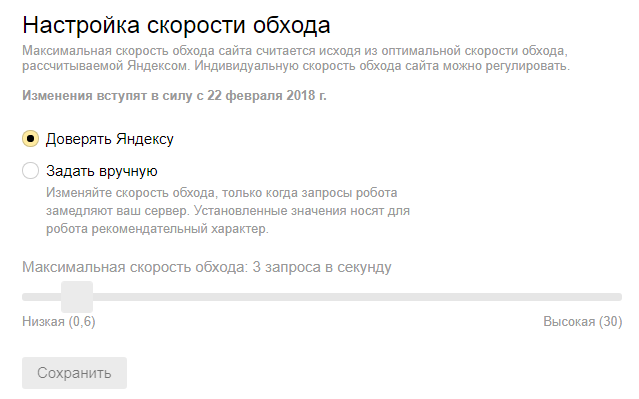
А с 22 февраля 2018 года в Яндекс.Вебмастере появилась новая фишка: Настройка скорости обхода. То есть, я так понимаю, что директиву Crawl-delay в файле robots.txt вполне может заменить эта настройка:
Проверка robots.txt в Yandex и Google
Для проверки robots.txt войдите в свои личные кабинеты web-мастеров Yandex или Google.
В Яндексе онлайн сервис доступен по ссылке
//webmaster.yandex.ua/robots.xml
В Google нужно перейти по адресу
//www.google.com/webmasters/tools/robots-testing-tool
Вот такой он, этот файл robots.txt!